AI Movie Explorer
Built from scratch with open-source LLMs and vector search, this post shares high-level technical details on how I created an AI-powered search that understands human language, not just keywords.
TL;DR: I built and launched an AI-powered Search user experience service with about 2 weeks of work.
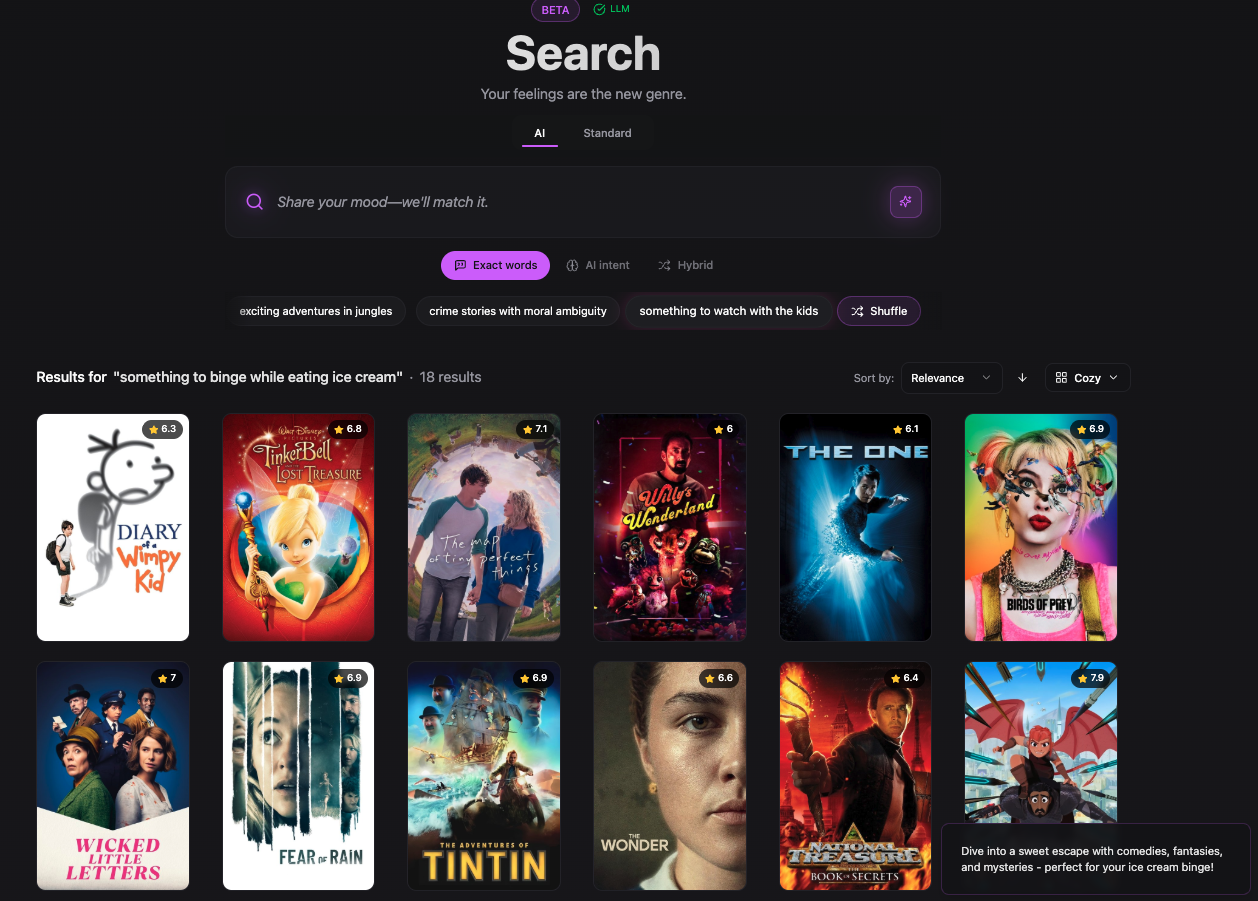
AI Movie Explorer landing page (click to enlarge)
The standard search is a straightforward implementation that connects directly to TMDb via real-time API calls. It returns fast results for text-based queries like movie titles, genres, or cast and crew names. The service makes direct requests to the TMDb API, applies a rate limit of 40 requests per 10 seconds, and is built to rely on fresh, real-time data at all times. It’s functional, fast, and works well when the user knows exactly what they’re looking for.
The AI-powered search is a more advanced, semantic search experience that lets users type in natural language queries like "I need a good cry" or "something funny after a long day." It uses a locally hosted open source LLM to extract intent from the user query through a prompt, then generates a 384-dimensional embedding using sentence-transformers. That vector is used to find similar matches in a Supabase database, where each movie or show already has its own embedding generated from enriched text. Popular and recent content is cached locally for speed, and the LLM helps present the final results in a conversational, entertaining way. It's a smarter, more intuitive way to explore content when users don't have a specific key word in mind but know the feeling they're after.
Google Gemini CLI integration for code generation and debugging (click to enlarge)
Claude Code CLI integration with Cursor (click to enlarge)
To build everything, I used Cursor as my main IDE, which made it easy to move fast with tight LLM integration. The frontend was built using Lovable, a lightweight AI powered platform designed to help users build full-stack web applications with a flexible UI that let me quickly shape the landing page user interface and experience. I used Gemini CLI and Claude Code throughout the development process to help generate, review, and debug code as I iterated. Frontend is built and deployed on Vercel, which handles builds and deployment with zero config, and I used Cloudflare Tunnels to expose my local Ollama open source LLM and embedding servers securely to the web, it is running outbound only, allowing the application to run smoothly during both testing and production.
AI-Powered Search Implementation: Technical Details
Open Source LLM Implementation with Ollama
The system now runs on Mistral 7B, a roughly seven-billion-parameter model that I serve locally through Ollama in its Q4 quantized build (≈4.1 GB on disk, ~8 GB RAM). In this configuration it cranks out 20-50 tokens per second on a modern CPU and packs an 8,192-token context window, giving me GPT-3.5-level performance for intent-extraction workloads while running on my local machine. Ollama bundles the weights and runtime in a neat, self-contained environment that acts like a single executable, and my LLM micro-service hits it over HTTP with prompts engineered to return just keywords and themes capped at 150 tokens, no explanations. When I first started building the app, I went with LLaMA-based open-source models for intent extraction. But a few weeks ago, OpenAI released two GPT-OSS models, gpt-oss-120b & gpt-oss-20b, and I decided to try integrating gpt-oss-20b. It looked promising on paper, but in practice it wasn’t the right fit, the model defaulted to long, chain-of-thought reasoning, so instead of returning a clean intent, it wanted to explain everything. The actual output would show up in the “thinking” portion of the payload, while the response itself was often empty. I tried parsing that output with regex and played around with generation parameters to force a more direct response, but none of it worked reliably and I did not wamt to spend too much time on this. After a couple of days debugging and testing edge cases, I dropped GPT-OSS and switched to Mistral 7B instead. It turned out to be exactly what I needed: fast, consistent, low hallucination, and focused entirely on pulling the intent from the query without extra noise.
Sentence Transformers and Vector Creation
The embedding generation relies on the all-MiniLM-L6-v2 model from Sentence Transformers, a BERT-based architecture with 6 transformer layers and roughly 22 million parameters. This model produces 384-dimensional embeddings from text inputs up to 256 tokens in length. The entire model occupies only 90MB in memory, making it extremely efficient for real-time inference. This entire process of capturing the user query and converting it into a vector completes extremely quickly. The 384-dimensional output represents a careful balance between storage efficiency and semantic richness.
Local Service Architecture
The LLM service runs as a Python FastAPI application, sending stateless HTTP requests to Ollama. Upon startup, it verifies the availability of the Mistral 7B model, and implements a caching layer with a 5-minute TTL for identical queries. The service exposes endpoints for query processing, health checks, and model listing, handling concurrent requests. The embedding service operates independently, also built with Python FastAPI. During initialization, it loads the Sentence Transformer model into RAM and performs a warm-up embedding to ensure the model is ready. Both services are loosely coupled in code, but a full search depends on calling them in tandem.
Vector Search Database Architecture
The PostgreSQL database with pgvector extension stores a subset of TMDb content embeddings in a highly optimized structure. Each movie record contains an enriched_text field that combines the title, overview, genres, emotional keywords, and exclusion terms. This enriched text was carefully crafted to maximize semantic accuracy. The corresponding 384-dimensional embedding vector is stored in a specialized vector column type, occupying 1,536 bytes per movie. The actual vector search executes as a single SQL query that computes cosine similarity between the query embedding and all relevant movie embeddings.
Cloudflare Tunnel Production Architecture
The production environment solves the challenge of accessing local LLM and embedding services from the public internet through Cloudflare Tunnels. Each service has a dedicated tunnel that creates a secure route from a public subdomain to the local service port. When a user makes a search request on aimovieexplorer.io, the React application calls Vercel Edge Functions at /api/llm-process or /api/embedding. These Edge Functions add Cloudflare Access credentials as headers. The authenticated request travels to the Cloudflare tunnel endpoint, where Cloudflare validates the credentials before routing the request through an encrypted connection to the local machine. Cloudflare Access policies enforce that only requests with valid service tokens can reach the tunneled services, preventing unauthorized access. The response from the local service travels back through the same tunnel, through the Vercel Edge Function, and finally to the user's browser, completing the round trip in typically 1-3 seconds depending on processing complexity.
Three Search Scenarios Implementation Rationale
Scenario 1: Search using only the original user query.
Scenario 2: Search using only the intents extracted by the LLM.
Scenario 3: A hybrid approach that combines the original user query with the LLM-extracted intents.
For testing the AI powered search UX, I implemented 3 scenarios. The exact words scenario processes the user's query directly without any LLM intervention, generating an embedding from the raw query text. This approach serves users results using their exact search query. The system bypasses LLM processing entirely, preserving the user's exact intent without interpretation.
The LLM intent extraction scenario transforms conversational queries into structured search concepts. When a user enters something like "I need a good cry but nothing scary," the Mistral 7B model extracts the core intent as "emotional drama, tearjerker, romance, NOT horror." This extracted intent becomes the text for embedding generation, effectively translating human expression into semantic search terms.
The hybrid scenario combines both approaches by concatenating the original query with the LLM-extracted intent before generating the embedding. For a query like "funny superhero movies," the system creates an embedding from "funny superhero movies, comedy, action, Marvel, humor, lighthearted." This combined text preserves the user's specific terminology while adding semantic context that might not be explicitly stated. The hybrid approach proves most effective for queries that mix specific terms with subjective descriptors and is useful if the LLM drops any important key words in the intent extraction process.
The implementation of all three scenarios addresses the fundamental problem that no single approach works optimally for all query types. Simple title searches fail with LLM processing that might over-interpret, while conversational queries fail with exact matching that cannot understand context or negation. The hybrid approach would add unnecessary complexity to straightforward searches while being ideal for mixed-specificity queries.

Database records showing results from all three search workflows (click to enlarge for detailed view)
Hybrid workflow – deep dive

Hybrid search workflow architecture (click to enlarge)
When a user selects the hybrid search mode and enters "something to binge while eating ice cream" the system initiates a multi-stage processing pipeline that combines natural language understanding with semantic search. The query first enters the React application, where the searchMovies function determines that hybrid mode requires both original query preservation and LLM enhancement. The system begins by routing the query to the vector search module, which recognizes the hybrid strategy and prepares for dual processing. The LLM service receives the query for intent extraction, and runs a prompt that requests the extraction of movie search concepts while maintaining the casual, comfort-focused nature of the original query. The Mistral 7B model, running locally through Ollama, processes this prompt at temperature 0.3 to ensure consistent and focused outputs rather than creative variations.
After processing, the LLM returns "relaxed, lighthearted, comedy, romance, family, feel-good, whimsical, colorful" as the extracted intent. The system then constructs the hybrid query by concatenating the original user input with the LLM-extracted intents, creating "something to binge while eating ice cream, relaxed, lighthearted, comedy, romance, family, feel-good, whimsical, colorful" as the final search text.
The combined text flows to the embedding service, where the Sentence Transformer model generates a 384-dimensional vector representation. This embedding captures both the specific context of binge-watching while eating ice cream and the broader emotional themes of comfort and lightheartedness. The embedding generation completes utilizing the all-MiniLM-L6-v2 model's understanding of semantic relationships. The resulting vector, stored as an array of 384 floating-point numbers travels to the Supabase PostgreSQL database for similarity matching. The database query computes cosine similarity between this query embedding and the pre-computed embeddings of a subset of TMDb content. Following the vector search completion, the system invokes the LLM presentation service to generate a contextual introduction for the results. The presenter examines the search results and the original query context, crafting a brief, witty introduction that acknowledges the user's desire for comfortable, binge-worthy content. This presentation layer adds a human touch to the search results, making the AI search feel more conversational and understanding of user intent. The hybrid approach demonstrates its value in this example by successfully combining the user's specific context of eating ice cream with the broader emotional themes that make content binge-worthy. Neither pure exact matching nor pure LLM intent would have captured both the specific activity context and the emotional mood as effectively. The exact approach would have struggled with the conversational nature of "something to binge," while pure LLM intent might have lost the specific context of comfort eating. The hybrid strategy preserves both elements.
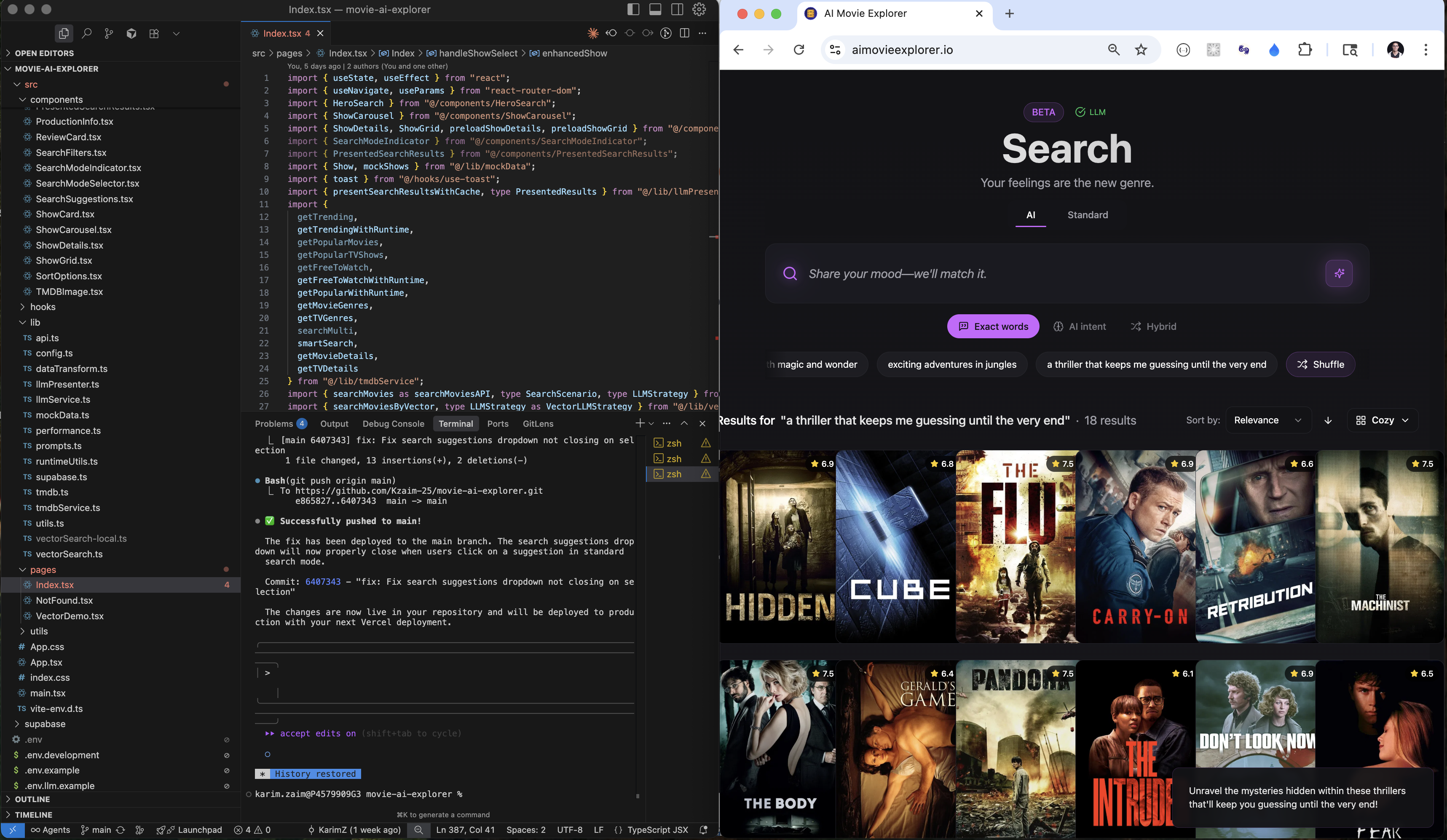
The AI-powered development experience: from prompt to production.
Overall, building the AI Movie Explorer gave me a front-row seat to how AI development tools are radically changing what it means to ship software. Not only did I leverage LLM capabilities to build the software but also delegated some of the app logic to the LLM to handle and integrate it in workflows within the application. I’m not a full-stack engineer by trade, and yet within two weeks I had a full semantic search engine running on local LLMs, with vector embeddings, Supabase integration, and three search strategies wired together into a single product. Tools like Cursor, Lovable, Claude Code, and Gemini CLI gave me superpowers and it felt awesome! The speed at which I could move wasn’t just fast, it was completely nonlinear. I’d write an idea down, and five minutes later it was live in my test environment. I started trusting the tools more and more: pasting in logs, iterating on prompts, reviewing PRs, and just testing the result in the UI. But that trust only worked because I kept a clean git history. The moment something broke, I could reset and try again. The biggest unlock was realizing that debugging isn’t about stack traces anymore, it’s about shaping the prompt or clarifying the goal. But that came with some pain too: LLMs love to guess, and more than once, the AI rewrote pieces of my API or silently changed the response structure, which broke the frontend. Refactoring also required surgical precision, if I wasn’t hyper-specific, it would reimplement identical logic in separate locations, delete files, or merge unrelated logic, and having a software engineering background proved to be very helpful to correct and redirect the AI when it was going rogue. What really blew my mind though was how deeply the tools could reach beyond code. I asked for a Cloudflare tunnel config, or setting up a Vercel build/deployment pipeline, managing my Git PRs or updating my documentation and the AI just handled it. The security reminders about API key exposure, or thoughtful feedback on architectural decisions, all of that felt like coding with a senior engineer on standby. When I hit a wall trying to get GPT-OSS to extract clean intents, I spent a few days troubleshooting before switching to Mistral 7B, which turned out to be the perfect fit. That kind of flexibility, swapping out an entire LLM model and re-prompting it into place, to extract intent from a user query would have taken days in a traditional setup pre LLMs. Looking back, the wildest part is how fast ideas/design turned into features and also the LLM did a great job on bugs fixing when I provided clear context. The real bottleneck wasn’t implementation, it was creativity! figuring out what to build next. I’ve never worked on a project where I felt so far ahead of my own to-do list : )
Have you implemented AI features in your product? I'd love to hear about your experiences and challenges. Connect with me on LinkedIn or Twitter.