Building a Cross-Modal AI Experience: From Image Analysis to Immersive Audio
Exploring the intersection of computer vision and generative audio by creating an app that analyzes images and generates matching soundscapes using open-source AI models.
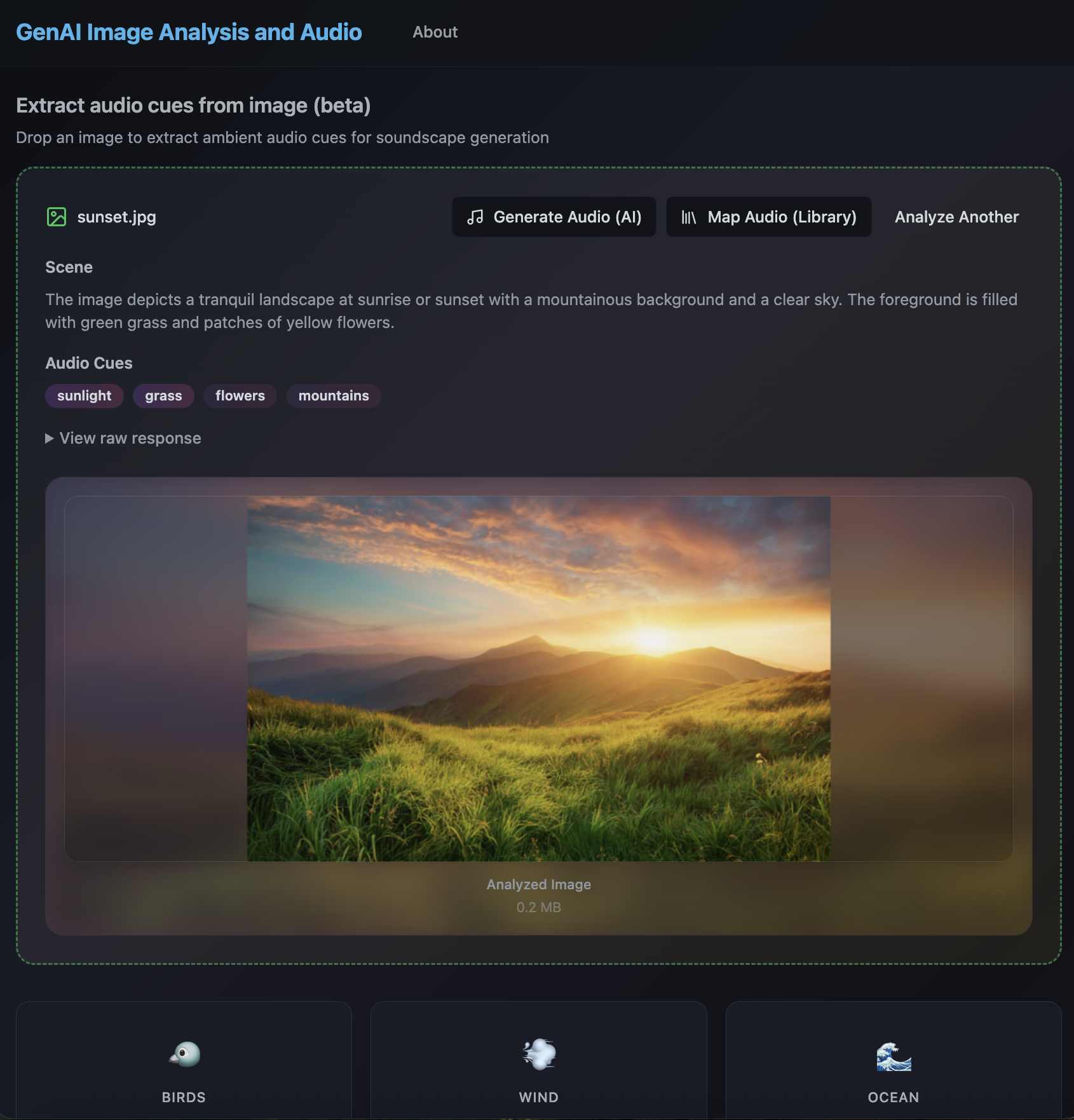
GenAI Image Analysis and Audio (click to enlarge)
From my past experience, I've worked with and tested ML-powered vision services such as AWS Rekognition and Google Vision AI. These services, which can be trained to recognize specific characters, impressed me with their accuracy. I used them in the context of QA automation, analyzing screenshots from a wide range of application UIs to flag layout issues, truncations, and text overlaps.
For this project, I wanted to go a step further by experimenting with open-source models: analyzing images, extracting audio cues, and passing them to a generative audio model to produce sound.
The app/experiment works by using computer vision to understand what's in an image, whether it's a forest, a beach, or a thunderstorm, and then either selecting appropriate sounds from a curated pre-computed library or generating new ones using AI audio models. The result is an immersive audio experience that matches the visual scene.
Vision Processing with LLaVA
At the core of the system, I integrated LLaVA (Large Language and Vision Assistant), an open-source vision model running locally through Ollama. LLaVA analyzes uploaded images to extract audio-relevant elements. For example, if you upload a photo of a mountain lake at sunset, LLaVA doesn't just identify "water" and "mountains." It understands the scene more holistically, picking up on elements that suggest sound: gentle waves lapping, wind through pine trees, maybe even distant bird calls. The model assigns salience scores to each element based on its visual prominence, which I then map directly into audio volume levels. This vision analysis is tied into a semantic mapping system I built with over 150 connections, handling synonyms, related concepts, and even abstract associations.
Dual Audio Generation Paths
The audio side offers two paths that users can choose from. One option is a curated library of 30+ high-quality ambient loops, categorized into nature, water, weather, and general ambience which provides instant playback for common scenarios. The other option leverages Meta's AudioGen model through a FastAPI backend, generating custom three-second ambient loops on demand for a more dynamic, AI-driven experience.
The audio management layer, built with React and TypeScript, supports multiple simultaneous streams through a custom hook that manages HTML5 Audio elements, individual volume controls, crossfading, and continuous looping.
Architecture & Implementation
From an architectural perspective, the system emphasizes local execution with open-source models, while the React frontend orchestrates communication between vision processing and audio generation services. What makes this experiment unique is how it bridges two different AI modalities: vision models understand the context and "feeling" of a scene, while audio models recreate that atmosphere through sound.
One current trade-off is performance: the curated library provides near-instant playback, but generating entirely new sounds through AudioGen can take significantly longer, since it relies on full generative AI processing. Still, the end result: a dynamic, multi-layered soundscape that evolves from a single image, feels like a compelling proof of concept for cross-modal AI.
Have you implemented AI features in your product? I'd love to hear about your experiences and challenges. Connect with me on LinkedIn or Twitter.